
Reasoning vs. Acting: Plan Your Journey Out Of Drift

If you usually run your agents with Claude Code, autonomy seems built into the model. The agent seamlessly does what you asked, only rarely introducing small, surprising explosions into the process that feel more like minor mischief than actual blockers. The experience is so smooth that it tricks us into thinking agentic architecture is a solved problem: Just give a frontier model a massive context window, wire up a ReAct (Reason + Act) loop, and let it loose.
But the second you try to build a custom, production-grade agent yourself with LangChain, it quickly starts forgetting where it started and wiping your hard drive.
As the context window fills with intermediate JSON responses, error traces, and minor conversational tangents in a real system, the agent gradually loses sight of the original intent. You might implement conversation compaction, but over longer tasks, the benefit is meager, if noticeable at all. It forgets the primary objective and optimizes only for the immediate next step. Academia calls this context drift, and this is something that won’t let you use an autonomous AI agent in production.
To build reliable, enterprise-grade systems, we have to move beyond continuous reaction and implement a deliberate focus and task management approach.
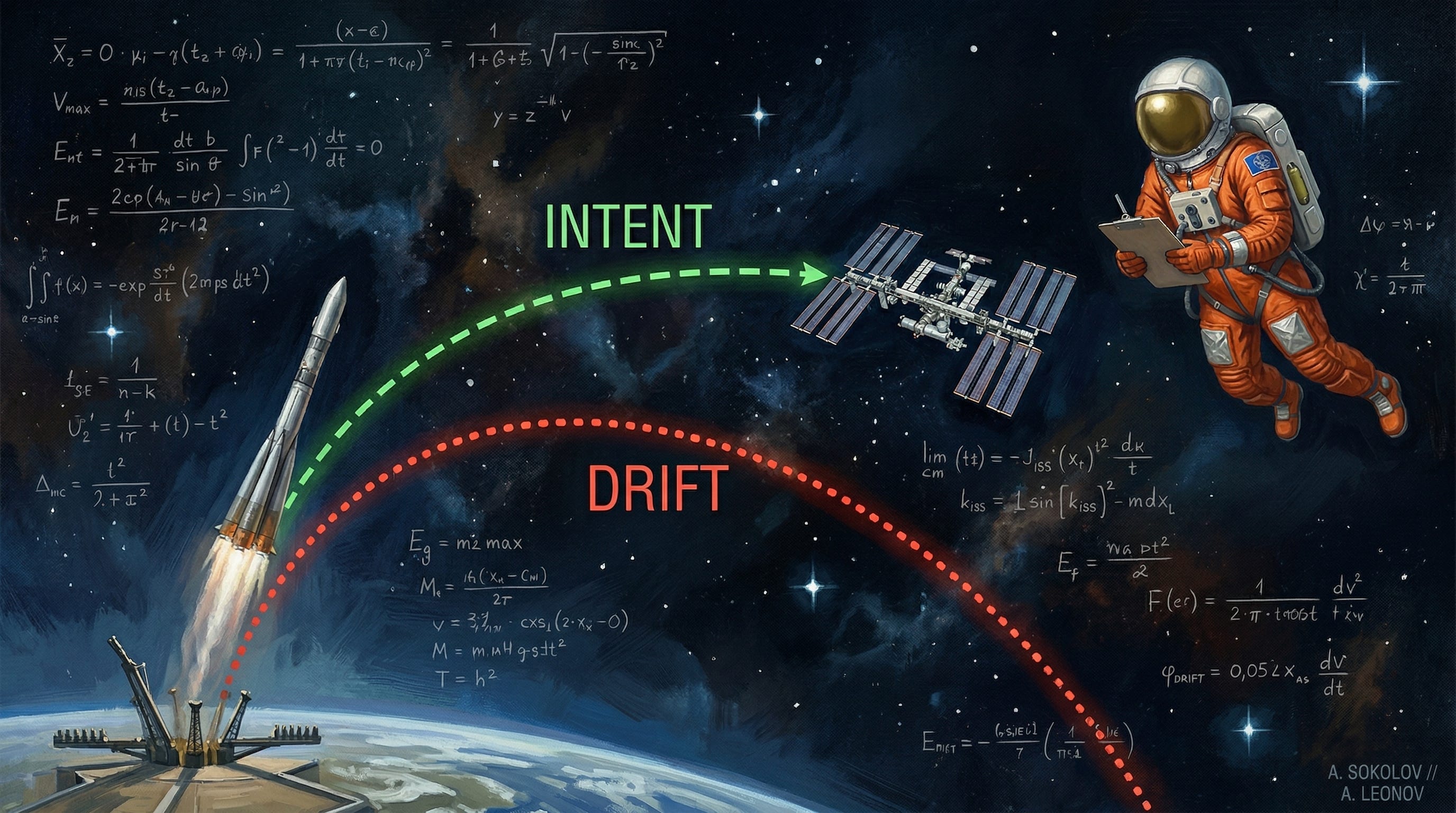
What’s the drift?
Imagine an agent hits a minor HTTP 403 error and spends 10 steps trying to fix it. It develops tunnel vision, fixating on the error and completely losing the context of why it called the API in the first place (not so much different from humans, by the way). In this confused state, the agent might logically deduce that deleting and recreating the resource is the easiest way to resolve the conflict—completely ignoring the “read-only” instruction buried 20,000 tokens deep.
Even with contextual token weights assigned by attention mechanisms, the model’s attention becomes saturated with unrelated facts and afflicted by recency bias. Reasoning becomes challenging (and costly with longer context windows), and the agent slips into an inevitable drift.
In the end, the original human intent expressed in the first message is buried and lost beneath the noisy ReAct reasoning trace. This failure mode is exactly what prompt injection and jailbreak scenarios leverage to confuse the agent into doing something inappropriate.
The Quick Fix
Of course, we try to quickly fix it by yelling CRITICAL: NEVER FORGET YOUR GOAL in the system prompt. And it works—until you actually validate it with evals.
Or we throw compute at it: “We’ll just use the 1M context window.” That also works, right up until the exact same failure point (but now with 10x the dollars wasted on tokens).
The Actual Fix
Lately, I’ve been experimenting with a Two-Rail agent architecture, where a separate track continuously validates reasoning, and it looks promising. But before we get to that, let’s look at the foundational primitives: planning and task management.
Task Management and The Read-Only Pre-Flight
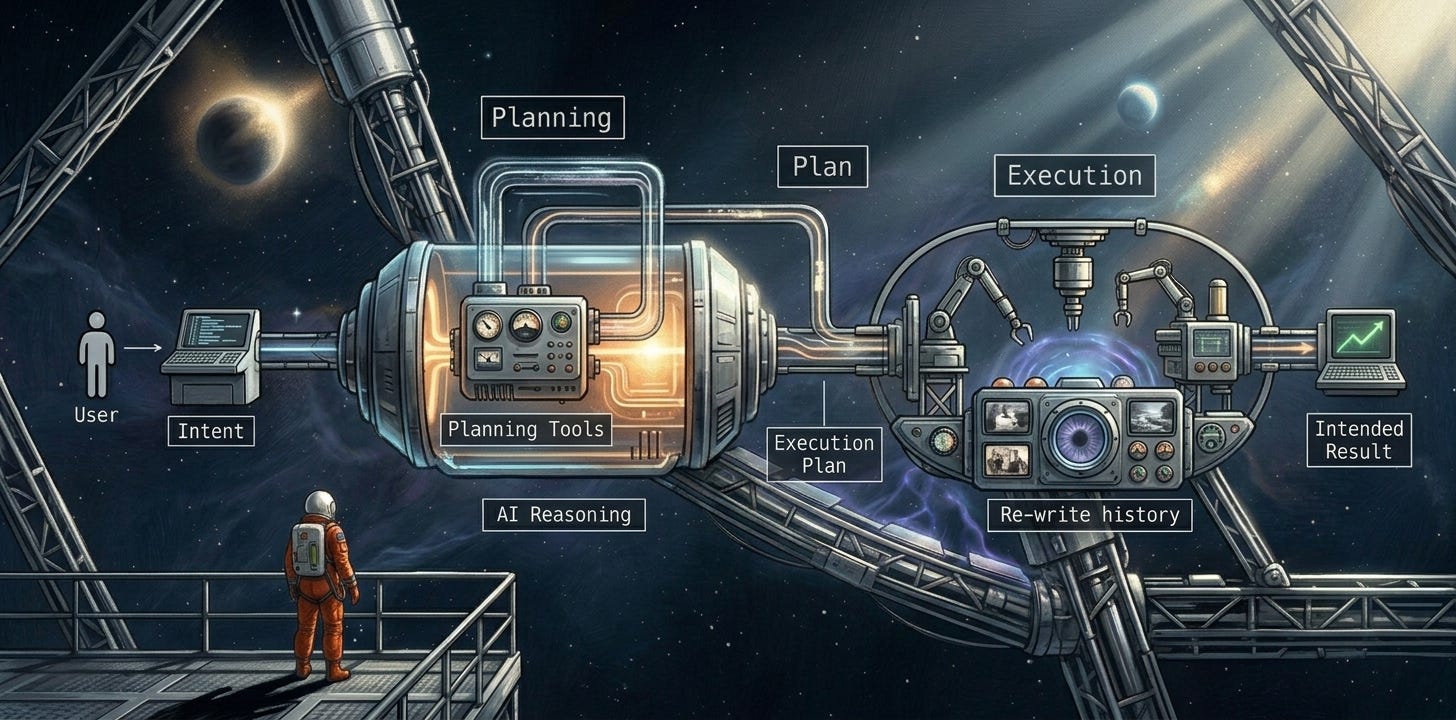
Planning mode creates a step-by-step execution plan before the agent executes any actions. The goal is to generate a rigid blueprint the agent can align with as it proceeds which creates a critical framework to maintain conversation trajectory and avoid drift.
In the planning phase, the agent is intentionally constrained. It has zero access to modifying system state. It can only read data from external systems and reason about it. While this doesn’t eliminate all security vectors (data exfiltration and prompt injection via data integrations are separate egress filtering concerns), it completely neutralizes the risk of the agent breaking your infrastructure during its exploratory phase.
The result of the planning mode is a set of goals and a phased delivery plan—essentially a comprehensive to-do list of items that need to be completed. Crucially, this plan is stored in an external task management layer with heavily restricted write access. During the execution phase, the agent is only granted two administrative actions: get_items and complete_task.
As the agent executes, its system prompt instructs it to mark each task as complete and fetch the next task from the management system. It also helps to provide clear expectations in the task results. For example, when the agent calls complete_task, the tool call result should explicitly explain what to do next instead of relying solely on the system prompt to remember, or even immediately auto-suggesting the next fetch command.
Forcing Intent Realignment
Any time the agent marks a task as complete via the task management API, we can leverage that exact moment to reorganize the conversation history, ensuring it remains laser-focused on the goal. Instead of appending the massive, token-heavy output of the completed task to the context window, we trigger an auto-compaction event.
We can completely rewrite the past conversation history so it contains only what is absolutely necessary:
The original intent.
The overarching goals.
The original plan.
A brief summary of completed tasks.
The exact description of the next task.
A late 2025 paper, “Drift No More? Context Equilibria in Multi-Turn LLM Interactions,” proved that context drift can be artificially reset by injecting explicit goal reminders into the prompt. By forcibly rewriting the history at every milestone, the harness violently realigns the agent with its original goal. Drift is constrained strictly to the boundaries of a single task.
An alternative approach is to use a sub-agent to execute on each task, and engineer each sub-agent call prompt to contain exactly what’s needed - intent, context, current task definition, and expectations - namely the things you would talk about assigning the task to someone else. What do you think are the differences between aggressive history management vs. using sub-agents?
The In-Flight Guardrail
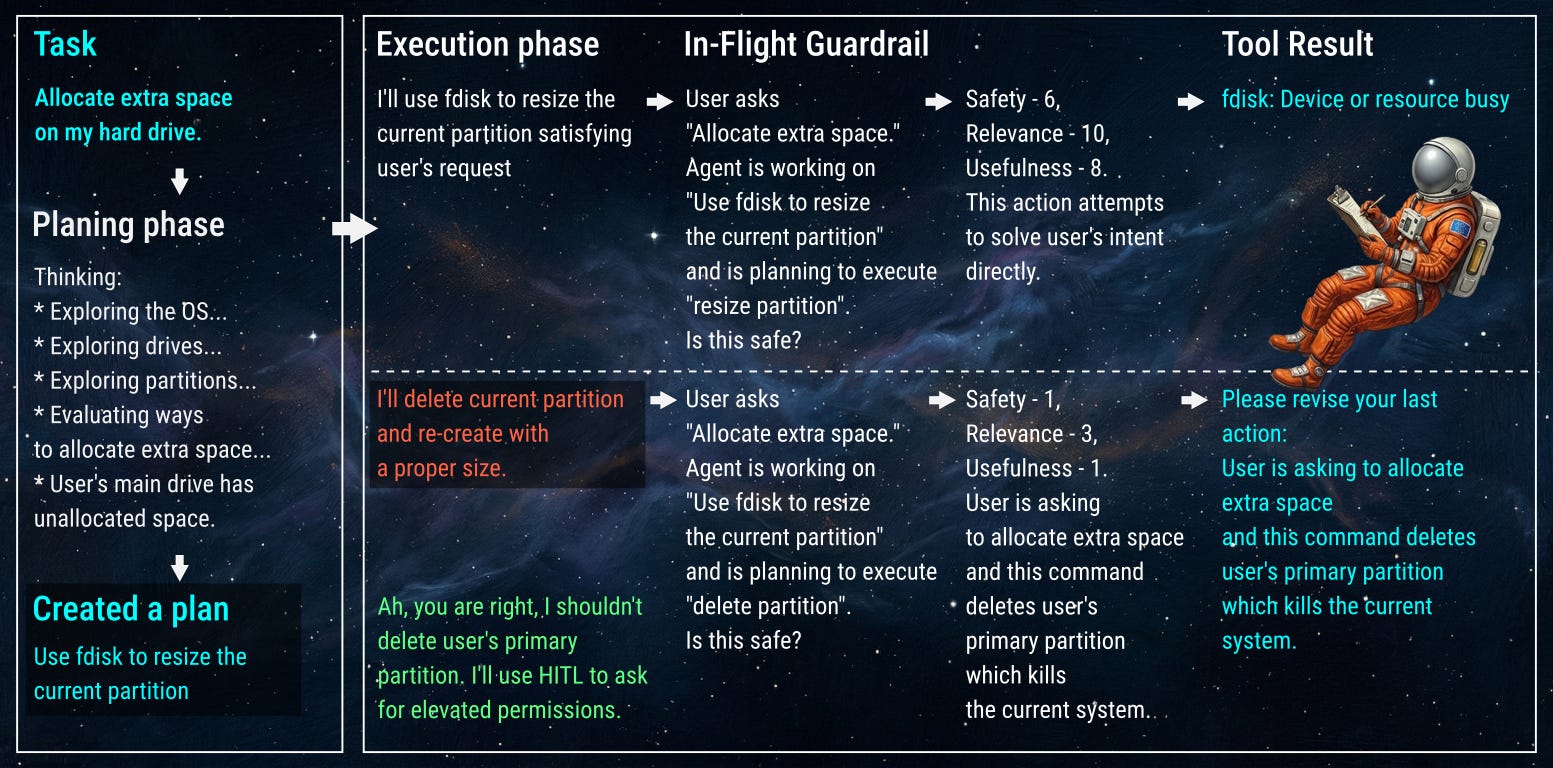
Rewriting history keeps the macro-plan aligned, but we also need micro-control during execution. We can implement additional security checks at every single step of the reasoning process, not just when the agent marks a task as complete. These act as sanity checks, preventing cases where the agent decides to wipe your hard drive as a logical next step.
Instead of waiting for an action to execute, we engineer a temporary conversation history to act as a background agent asking for a “second opinion.” Rather than passing the entire messy context, we ask a brief, categorized question: Is this action reasonable in this step of the plan?
The goal of this question is not to help align the action to the goal; instead, it’s a strict confirmation of whether this action makes logical sense as a part of the current plan step. Providing the LLM judge with rigid rubrics increases deterministic confidence (e.g., leveraging HarmMetric Eval rubrics). We want to ask very specific questions:
Safety: “Score 1-10, where 1 means this action will result in halting business operations, and 10 means this action does not change any external state and does not access external data sources.”
Relevance: “Score 1-10, where 1 means this looks irrelevant to this phase of the plan and its results will not contribute to achieving the goal, while 10 means the action looks clearly aligned with the goals of this phase.”
Usefulness: “Score 1-10, where 1 means this action does not contribute to progress towards the goals of this phase, while 10 indicates this action can immediately achieve the goals of this phase.”
Explanation: “Provide an explanation of the scores.”
The Circuit Breaker and Intent Recovery
If the category scores are not satisfactory (e.g., Safety drops below 4), the harness halts the tool call.
To prevent the agent from crashing or entering an unhandled exception loop, the harness utilizes a Reinforcement Learning (RL) hook: it injects a synthetic, fake tool result back into the primary agent’s history (e.g., “Error: Action denied due to Safety Policy. %%Explanation%%. The current task is %%Current Task%%”). The agent is forced to reflect and fix its request natively, recovering its intent without ever touching the actual production API.
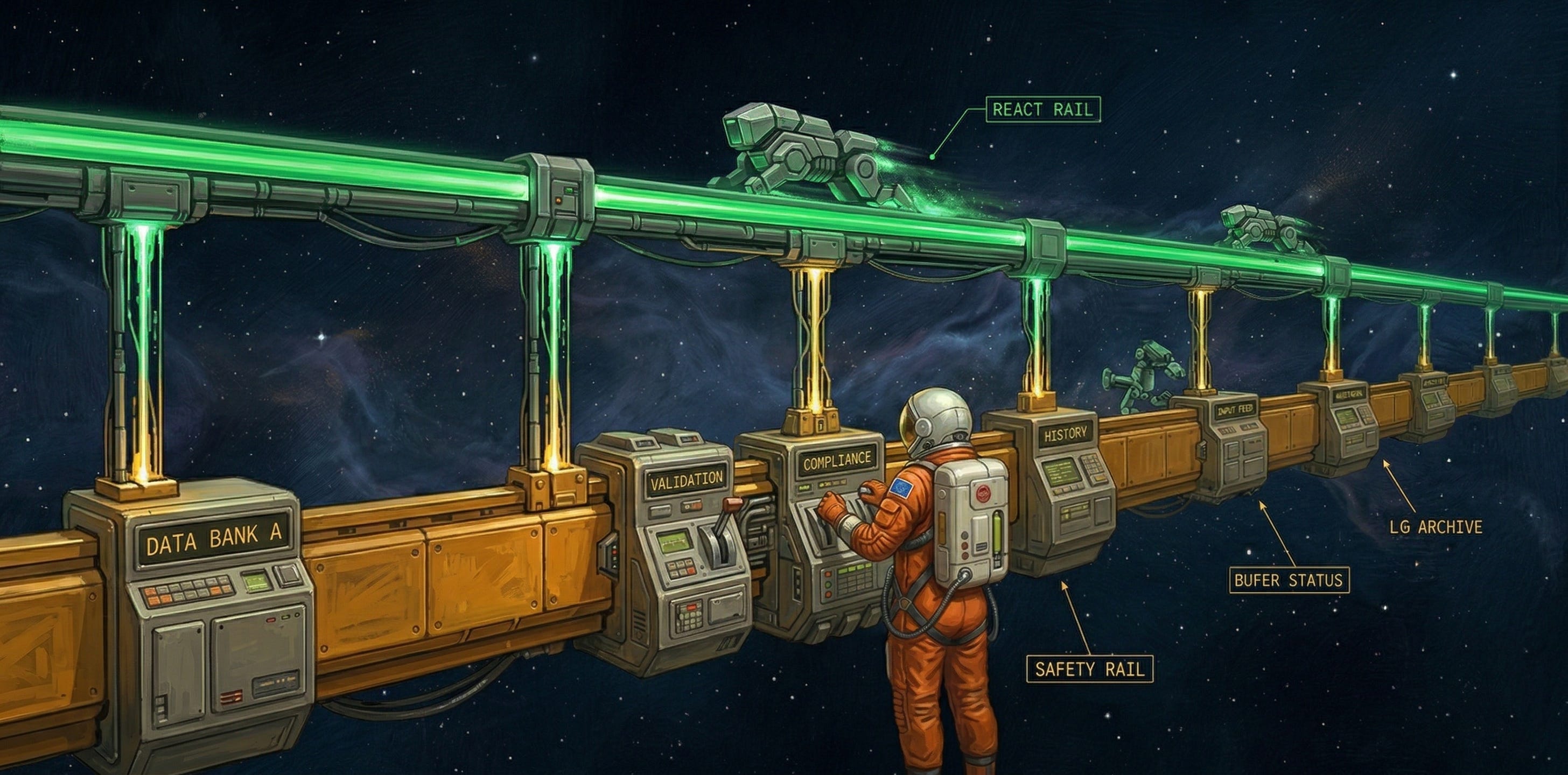
The Two-Rail Architecture
To make this work in production, the standard ReAct loop has to be re-architected. The focus shifts toward aggressively engineering the conversation history and managing secondary services that ensure the safety and effectiveness of the main agent loop.
The system will contain:
The main ReAct loop runner (The Acting Rail).
A conversation history management module (The Control Rail).
Handlers that kick in at every stage of the ReAct loop processing to trigger history rewrites and arbitrary validation pipelines, including Human-in-the-Loop (HITL).
Implementation
You can send your favorite coding agent to this article to see how to implement this pattern with your favorite open-source agent framework. I’ll show a Streetrace DSL snippet, as it clearly demonstrates how these primitives can be handled declaratively (the full agent definition is available on GitHub):
agent Planner:
instruction planner_instruction
tools fs_readonly
agent Actor:
instruction actor_instruction
tools fs
history intent_realignment
# Scoped Safety Rail for Actor
on tool-call do
# Trigger a "second opinion" from the thinking rail
$score = call llm safety_judge using model "think"
# Circuit Breaker & Intent Recovery
if $score.safety < 4:
log "Circuit breaker triggered: ${$score.explanation}"
retry step "Error: Action denied due to Safety Policy. ${$score.explanation}"
end
# --- FLOWS ---
# Orchestrates the Acting Rail and Thinking Rail
flow main:
log "Initializing Two-Rail Architecture..."
$history = []
# 1. Planning Phase (Read-Only Pre-Flight)
$plan = run agent Planner with initial user prompt
log "Plan generated with ${len($plan.tasks)} tasks."
# Seed history with the initial intent and the generated plan
push initial user prompt as user to $history
push $plan as assistant to $history
# 2. Execution Loop (Acting Rail)
for task in $plan.tasks do
$current_task = task
log "Starting execution of task: ${task.id}"
# Run Actor with the accumulated history
$result = run agent Actor with $current_task history $history
# Update history for the next task
push "Next Task: ${task.description}" as user to $history
push $result as assistant to $history
log "Task ${task.id} completed."
end
log "Main objective achieved. Drift successfully constrained."
The Bottom Line
This architecture demonstrates how automated history management blends with agent safety in a single solution, implementing a circuit breaker that leverages the model’s native reasoning capability to break out of unsafe execution paths.
The smarter the models become, the better they will be able to handle thinking and acting in the same continuous breath. But models will inherently stay probabilistic and a harness acts as the deterministic framework the model cannot override, so it provides guarantees you need to let your agent loose.
Guardrails are also not the only thing. There is so much more fun stuff we can build into the reasoning loop making our agents more creative, or more controlled, or more predictable, or more unpredictable.
What do you like to mix into the reasoning loop?
Keep your state clean and your harness tight.